
Implementation Details of Basic-and-Fast-Neural-Style-Transfer
Published:
Neural style transfer (NST) serves as an essential starting point those interested in deep learning, incorporating critical components or techniques such as convolutional neural networks (CNNs), VGG network, residual networks, upsampling and normalization. The basic neural style transfer method captures and manipulates image features using CNNs and the VGG network directly over the input image. In contrast, the fast neural style transfer method employs a dataset to train an inference neural network that can be used for real-time style transfer. This blogs provides the explanation of the implementation of both methods. Corresponding repository can be found here.
Basic NST
Method Overview:
The basic neural style transfer method uses a pre-trained VGG19 network to extract features from input images (content and style images). The training process involves minimizing a loss function that combines content and style losses. Content loss measures differences in feature representations, while style loss measures differences in correlations between features (Gram matrices). The input content image is iteratively updated using backpropagation to minimize these losses.
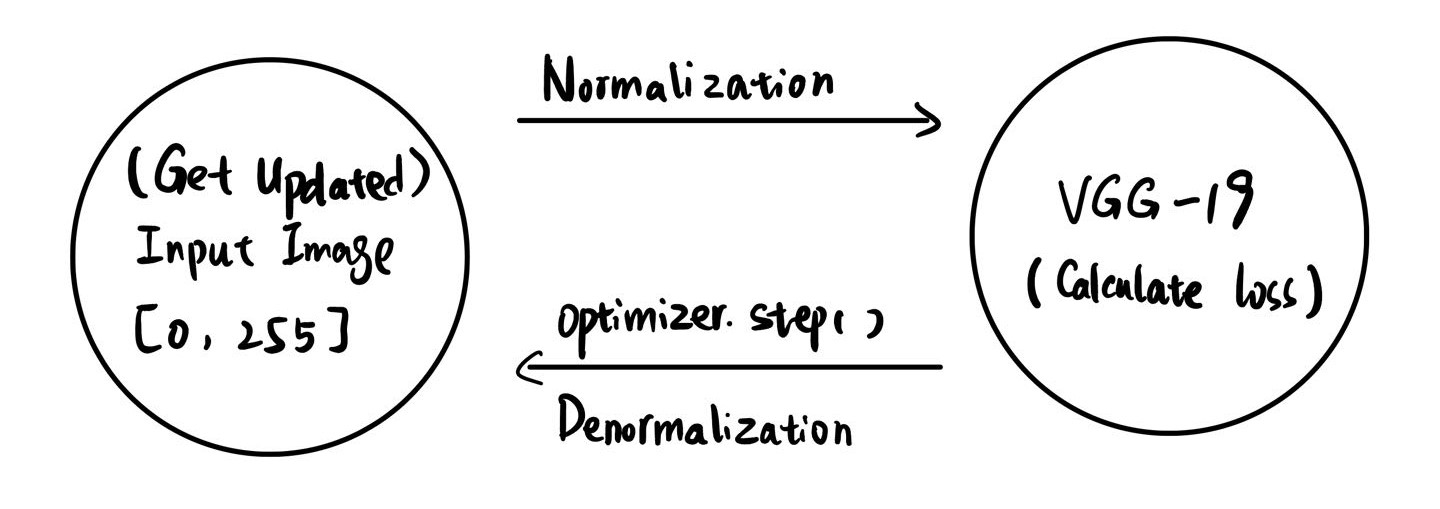
VGG-19:
VGG (Visual Geometry Group) Network is a deep convolutional neural network architecture developed by the Visual Geometry Group at the University of Oxford. VGG-19 is used in this implementation and it is one of the variants, characterized by its depth and simplicity in terms of the use of small (3x3) convolution filters. The number “19” indicates the network has 19 layers with learnable parameters, including 16 convolutional layers, 3 fully connected layers, and 5 max-pooling layers. Below is the structure information of VGG-19 printed out from pytorch:
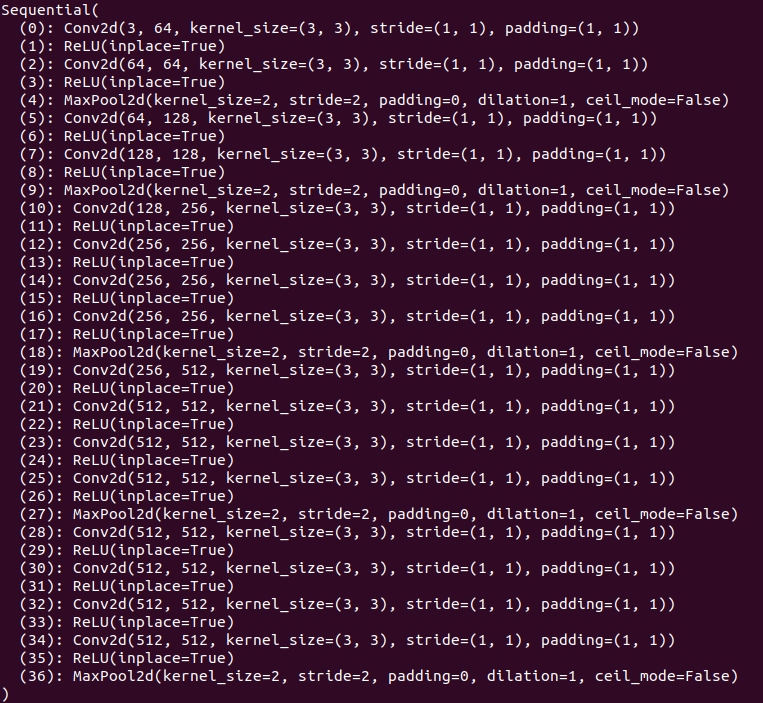
Information of each layers in VGG-19 Noted that VGG-19 is just used for calculating the loss function for updating the input content image. The parameter of VGG-19 itself is NOT updated during training process. Each of its important component is listed below:
- Convolutional Layers: Extract spatial features from the input image.
- Max-Pooling Layers: Downsample the feature maps, reducing the spatial dimensions.
- Fully Connected Layers: Act as classifiers (usually used in the original VGG for classification tasks).
Reasons for Choosing Specific Layers
class VGG(nn.Module): def __init__(self): super(VGG, self).__init__() # set index of layers of interest for computing loss self.select_features = ['0', '5', '10', '19', '28'] # load pre-trained VGG19 model and extracts only feature extraction layers (conv layers), # excluding the fully connected layers self.vgg = models.vgg19(pretrained = True).features print(self.vgg) def forward(self, x): # store output of feature maps from selected layers features = [] for name, layer in self.vgg._modules.items(): # apply current layer's operation x = layer(x) if name in self.select_features: features.append(x) return features- The choice of layers ensures that we capture both fine-grained details (from shallow layers) and more abstract features and structures (from deeper layers).
- This combination helps in effectively transferring the style while maintaining the content structure. In the context of neural style transfer, the VGG19 network is used as a feature extractor. Specifically, we use the feature maps from certain layers of VGG-19 to compute the content and style losses.
Loss Functions:
Content Loss: Measures how much the content in the generated image differs from the content image. The content loss is computed as:
\[\mathcal{L}_\text{content} = \frac{1}{2} \sum_{i,j} \left( F_{ij}^{C} - F_{ij}^{G} \right)^2\]where \(F_{ij}^{C}\) and \(F_{ij}^{G}\) are the feature representations of the content image and the generated image, respectively.
Style Loss: Measures how much the style of the generated image differs from the style of the style image using Gram matrices. The style loss is computed as:
\[\mathcal{L}_\text{style} = \frac{1}{4N^2M^2} \sum_{i,j} \left( G_{ij}^{S} - G_{ij}^{G} \right)^2\]where \(G_{ij}^{S}\) and \(G_{ij}^{G}\) are the Gram matrices of the style image and the generated image, respectively. According to the reference [1]: \(N\) denotes the number of feature maps (or channels), and \(M\) is the total number of elements in each feature map (height x width). In the implementation, the gram matrix is normalized, where \(c, h\) and \(w\) correspond to the number of channels, image height and width, respectively.
# calculate style loss style_loss = 0 for output_img_feature, style_img_feature, layer in zip(output_img_features_all, style_img_features_all, vgg.select_features): _, c, h, w = output_img_feature.size() output_img_gram = utils.get_gram_matrix(output_img_feature) style_img_gram = utils.get_gram_matrix(style_img_feature) # normalize the gram matrices for style loss style_loss += mse_loss(output_img_gram, style_img_gram) / (c*h*w) style_loss *= betaDirectly optimize on the input content image:
To improve the training efficency, the starting point of iteration is choosen to be the input content image.
Results
- Style images:



Used style images from portrait of different artists: Claude Monet, Vincent van Gogh, Pablo Picasso (from let to right) - Content images:


Two input content images: minion1 (left) and minion2 (right), minion2 is only used for testing fast NST. - Ouput of minion1:



Fast NST
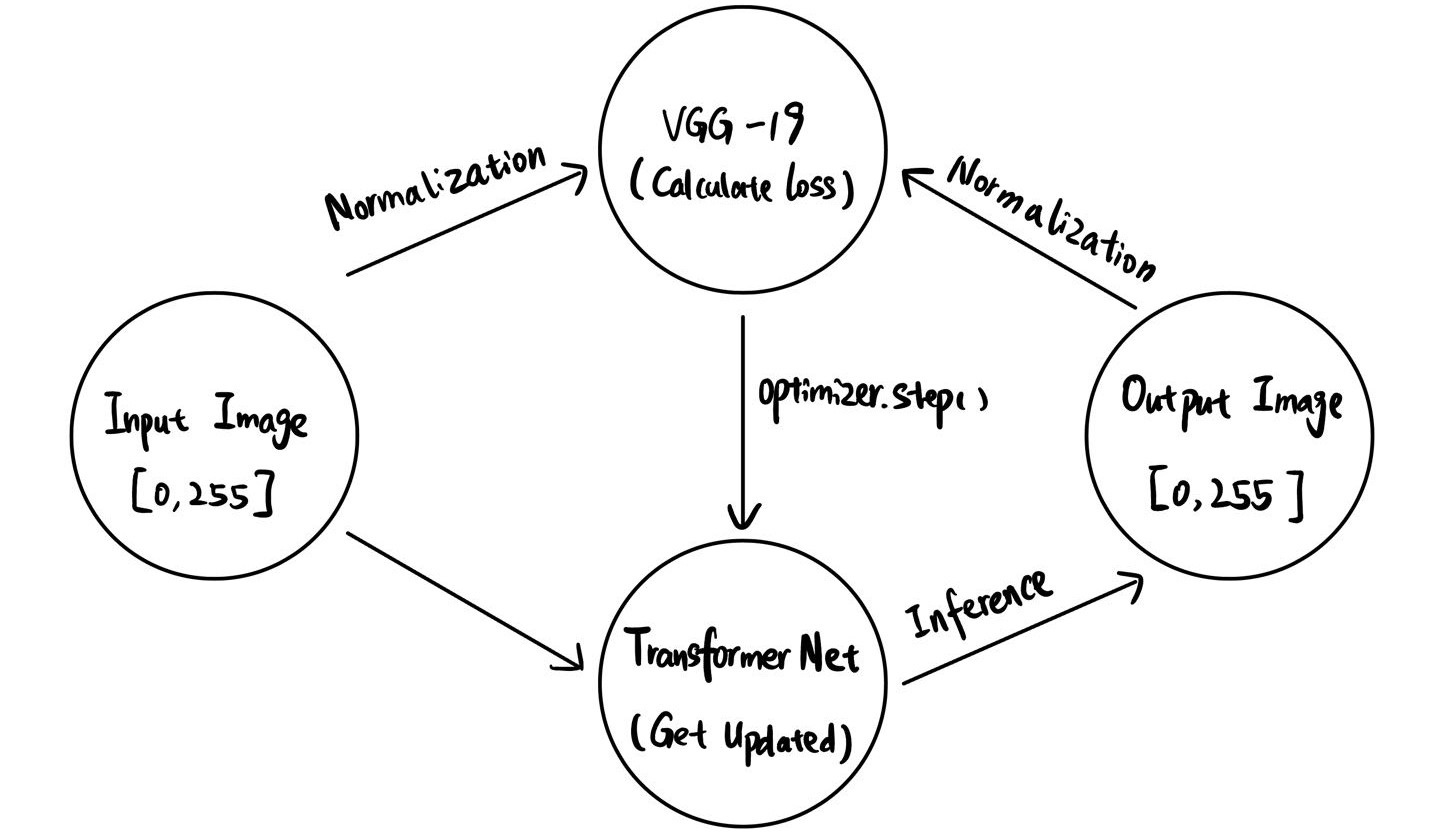
Method Overview
Fast neural style transfer trains a feedforward network (TransformerNet) to apply a specific style to any content image in a single pass. The network is trained using a perceptual loss function, which combines content and style losses obtained from a pre-trained VGG-19 network. The trained model then performs real-time style transfer.
Residual Block
Regarded as one of the cornerstones in the field of deep learning, residual neural network (ResNet) introduces skip connections, which allow the input to bypass certain layers and be added directly to the output of a deeper layer. This technique addresses the vanishing gradient problem, enabling the training of much deeper networks by ensuring gradients can flow through the network more effectively.
In the context of neural style transfer, residual blocks help retain the content and structure of the original image while allowing the network to apply the style transformation. The skip connections ensure that even as the image undergoes various transformations, the original content information is preserved and added back to the transformed features.
UpsampleConv Layer
Based on the pytorch official implementation on fast NST [4]: “Upsamples the input and then does a convolution. This method gives better results compared to ConvTranspose2d”. The first component of this module is the upsampling layers, which are used to increase the spatial resolution of feature maps. There are several methods to achieve upsampling, including:
- Nearest Neighbor Interpolation: Simply repeats the nearest pixel values.
- Bilinear/Trilinear Interpolation: Performs linear interpolation over two or three dimensions.
- Transposed Convolution: Also known as deconvolution, it applies learned filters to upsample the input.
UpsampleConvLayer combines an upsampling operation followed by a convolution to refine the upsampled feature maps, helping to reduce artifacts like checkerboard patterns. In neural style transfer, the role of UpsampleConv Layer can be summarized as follows:
- Resolution Restoration: They increase the spatial resolution of the feature maps back to the original image size.
- Detail Enhancement: Combined with convolution, they help refine the upsampled features to enhance image details and reduce artifacts.
Results
- Ouput of minion1:



a = 1, b = 50000 for all models - Ouput of minion2:



a = 1, b = 50000 for all models
References
- Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. “A Neural Algorithm of Artistic Style.” arXiv preprint arXiv:1508.06576 (2015) (Basic NST Paper)
- Neural Style Transfer (NST) — theory and implementation
- Johnson, Justin and Alahi, Alexandre and Li, Fei-Fei. “Perceptual losses for real-time style transfer and super-resolution.” European Conference on Computer Vision. 2016 (Fast NST Paper)
- pytorch/examples/fast_neural_style (Fast BST Implementation)
- Downsampling and Upsampling of Images — Demystifying the Theory
- iCartoonFace Dataset