
Sitemap
A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Pages
Posts
Interpreting LQR through Optimal Control and Reinforcement Learning Permalink
Published:
This post explains the Linear Quadratic Regulator (LQR) from two complementary viewpoints: classical optimal control and reinforcement learning. Starting from the finite- and infinite-horizon optimal control formulation, it derives the Riccati equation and optimal feedback law, then reinterprets the same results through value functions, Q-functions, policy iteration, and value iteration. Drawing on the connection highlighted in Reinforcement Learning and Adaptive Dynamic Programming for Feedback Control, the post shows how LQR serves as a clean bridge between control theory and RL, clarifying how dynamic programming ideas underpin both frameworks.
Implementation Details of TD3-SAC-Gymnasium Permalink
Published:
Twin Delayed Deep Deterministic Policy Gradient (TD3) and Soft Actor-Critic (SAC) are off-policy actor-critic algorithms designed for continuous control tasks where classic DDPG can be unhandy. TD3 stabilizes learning with tricks such as double Q-networks, delayed policy updates, and target policy smoothing to reduce overestimation bias. SAC instead learns a stochastic policy by maximizing both task reward and entropy, encouraging robust and exploratory behaviors. This blog post explains core components and implementation details of both algorithms. Corresponding PyTorch implementation can be found at this repository.
Implementation Details of Cartoon-VAE-Diffusion Permalink
Published:
Variational Autoencoder (VAE) learns to compress data into a latent Gaussian space and reconstruct it in a single shot. Denoising Diffusion Probabilistic Model (DDPM) tackles the same evidence-lower-bound objective from another direction: it begins with pure noise and iteratively denoise through hundreds of steps, exchanging speed for high-fidelity, stable synthesis. Both frameworks connect random noise to data, yet VAE rely on an explicit encoder–decoder pair, whereas DDPM use a learned Markov chain that inverts a forward noising process. This blog traces the progression from VAE to DDPM, clarifying their shared principles, with code examples available at this repository.
Shed Some Light on Proximal Policy Optimization (PPO) and Its Application Permalink
Published:
Proximal Policy Optimization (PPO) is a reinforcement learning algorithm that refines policy gradient methods like REINFORCE using importance sampling and a clipped surrogate objective to stabilize updates. PPO-Penalty explicitly penalizes KL divergence in the objective function, and PPO-Clip instead uses clipping to prevent large policy updates. In many robotics tasks, PPO is first used to train a base policy (potentially with privileged information). Then, a deployable controller is learned from this base policy using imitation learning, distillation, or other techniques. This blog explores PPO’s core principle, with code available at this repository.
From Q-Learning to Deep Q-Learning and Deep Deterministic Policy Gradient (DDPG) Permalink
Published:
Q-learning, an off-policy reinforcement learning algorithm, uses the Bellman equation to iteratively update state-action values, helping an agent determine the best actions to maximize cumulative rewards. Deep Q-learning improves upon Q-learning by leveraging deep Q network (DQN) to approximate Q-values, enabling it to handle continuous state spaces but it is still only suitable for discrete action spaces. Further advancement, Deep Deterministic Policy Gradient (DDPG), combines Q-learning’s principles with policy gradients, making it also suitable for continuous action spaces. This blog starts by discussing the basic components of reinforcement learning and gradually explore how Q-learning evolves into DQN and DDPG, with application for solving the cartpole environment in Isaac Gym simulator. Corresponding code can be found at this repository.
Dwell on Differential Dynamic Programming (DDP) and Iterative Linear Quadratic Regulator (iLQR) Permalink
Published:
Although optimal control and reinforcement learning appear to be distinct field, they are, in fact closely related. Differential Dynamic Programming (DDP) and Iterative Linear Quadratic Regulator (iLQR), two powerful algorithms commonly utilized in trajectory optimizations, exemplify how model-based reinforcement learning can bridge the gap between these domains. This blog begins by discussing the fundational principles, including Newton’s method and Bellman Equation. It then delves into the specifics of the DDP and iLQR algorithms, illustrating their application through the classical problem of double pendulum swing-up control.
Implementation Details of Basic-and-Fast-Neural-Style-Transfer Permalink
Published:
Neural style transfer (NST) serves as an essential starting point those interested in deep learning, incorporating critical components or techniques such as convolutional neural networks (CNNs), VGG network, residual networks, upsampling and normalization. The basic neural style transfer method captures and manipulates image features using CNNs and the VGG network directly over the input image. In contrast, the fast neural style transfer method employs a dataset to train an inference neural network that can be used for real-time style transfer. This blogs provides the explanation of the implementation of both methods. Corresponding repository can be found here.
On Derivation of Hamilton-Jacobi-Bellman Equation and Its Application Permalink
Published:
The Hamilton-Jacobi-Bellman (HJB) equation is arguably one of the most important cornerstones of optimal control theory and reinforcement learning. In this blog, we will first introduce the Hamilton-Jacobi Equation and Bellman’s Principle of Optimality. We will then delve into the derivation of the HJB equation. Finally, we will conclude with an example that shows the derivation of the famous Algebraic Riccati equation (ARE) from this perspective.
From Control Hamiltonian to Algebraic Riccati Equation and Pontryagin’s Maximum Principle Permalink
Published:
Inspired by the Hamiltonian of classical mechanics, Lev Pontryagin introduced the Control Hamiltonian and formulated his celebrated Pontragin’s Maximum Principle (PMP). This blog will first discuss general cases of optimal control problems, including scenarios with both free final time and final states. Then, the derivation of Algebraic Riccati Equation (ARE) in the context of Continuous Linear Qudratic Regulator (LQR) from the perspective of the Control Hamiltonian will be introduced. It will then explain the PMP, finally followed by the example problem of Constrained Continous LQR.
On Derivation of Euluer-Lagrange Equation and Its Application Permalink
Published:
Euler-Lagrange equation plays an essential role in calculus of variations and classical mechanics. Beyond its applications in deriving equations of motion, Euler-Lagrange equation is ubiquitous in the filed of trajectory optimization, serving as a critical stepping stone for many powerful optimal control techniques, such as Pontrygain’s Maximum Principle. In this blog, derivation of the Euler-Lagrange equation and two simple cases of its application are introduced.
portfolio
▪ Basic-and-Fast-Neural-Style-Transfer
Simplified implementation of basic neural style transfer and fast neural style transfer in PyTorch.
[Blog Post] [Code]
▪ Cartoon-VAE-Diffusion
Minimal implementation of VAE and diffusion models for cartoon images generation..
[Blog Post] [Code]


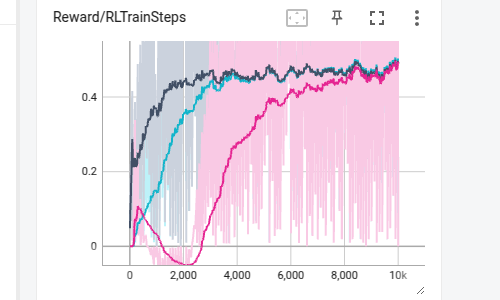
▪ Cartpole-DQN-DDPG-PPO
Minimal implementation of RL algorithms (DQN, DDPG and PPO) in Isaac Gym cartpole environment.
[Code] [Blog Post 1] (DQN & DDPG) [Blog Post 2] (PPO)

▪ Motion-Planning-MPC
Modular implementation of basic motion planning algorithm that based on Model Predictive Control (MPC) and Control Barrier Function (CBF).
[Code] [Slide]
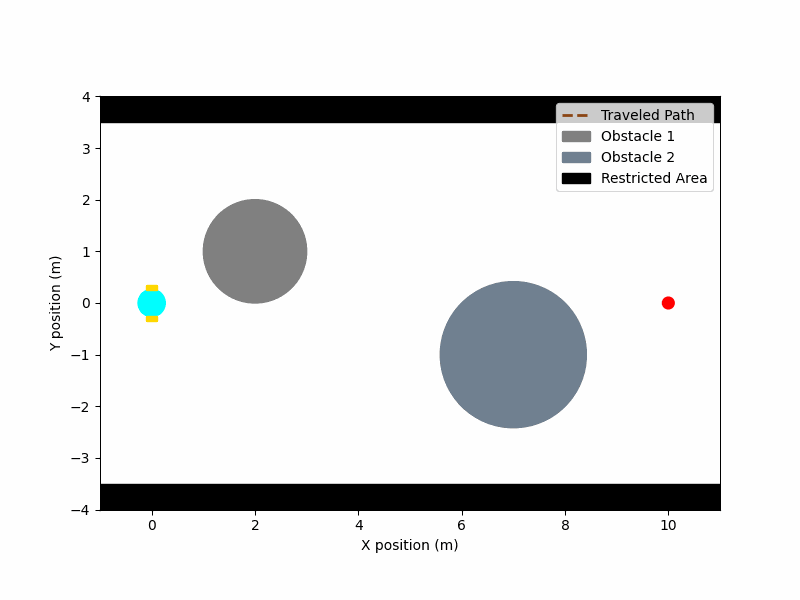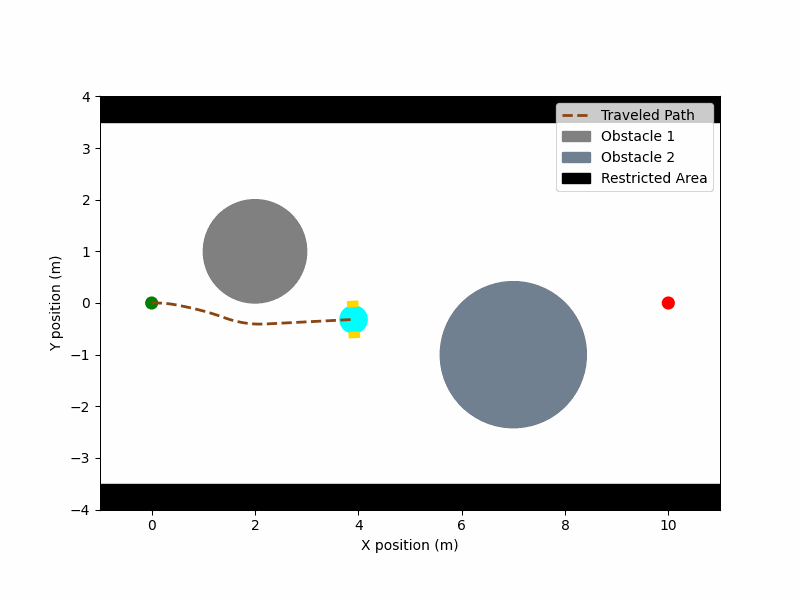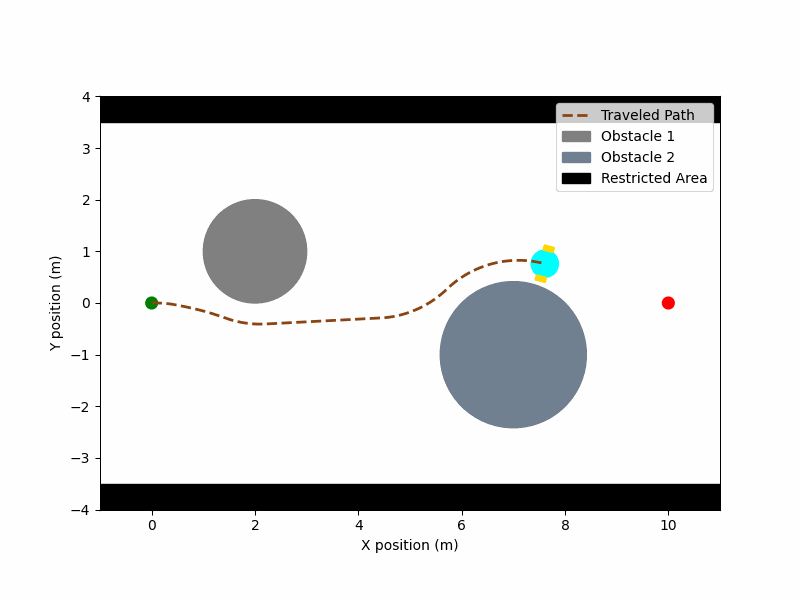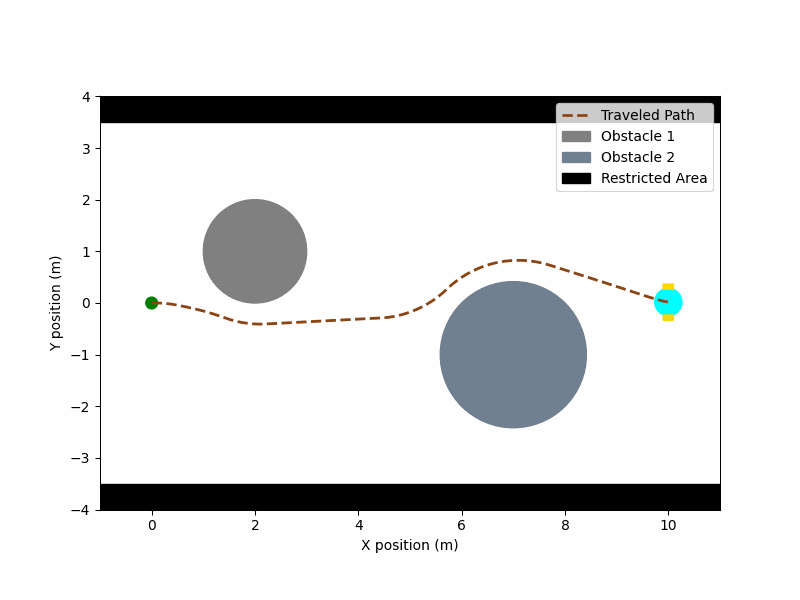
▪ MuJoCo-RMP2-PyTorch
Collection of small-scale projects for testing robotics algorithms in the MuJoCo simulator. (Ongoing project)
[Code] [Blog Post]

▪ Simple-MPC-CBF
Simple scripts that are used for solving motion planning & obstacle avoidance problems via Model Predictive Control (MPC) & Control Barrier Function (CBF).
[Code] [Report] [Slide]

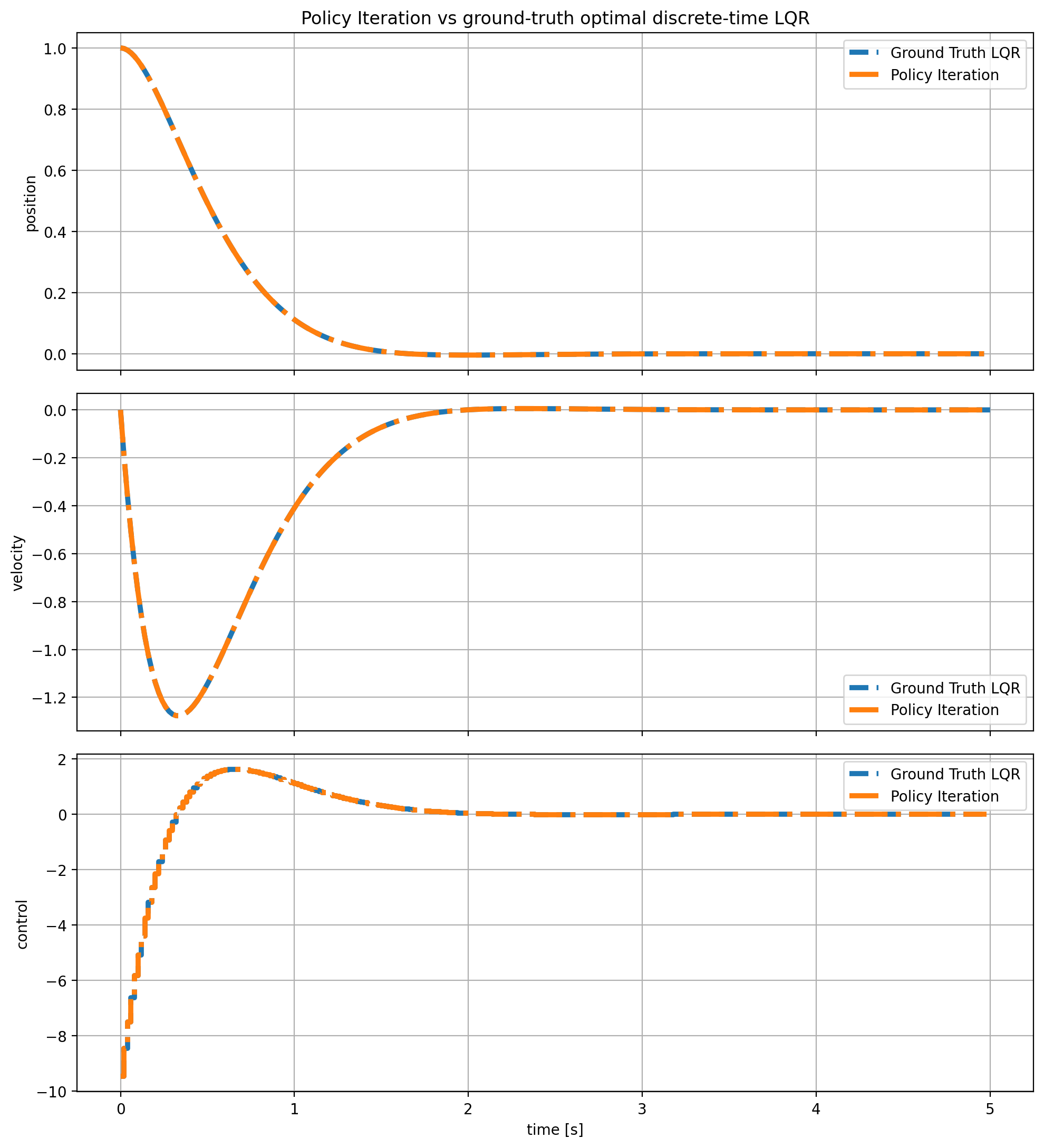
▪ Solve-LQR-3Ways
Modular implementation of basic motion planning algorithm that based on Model Predictive Control (MPC) and Control Barrier Function (CBF).
[Code] [Blog Post]
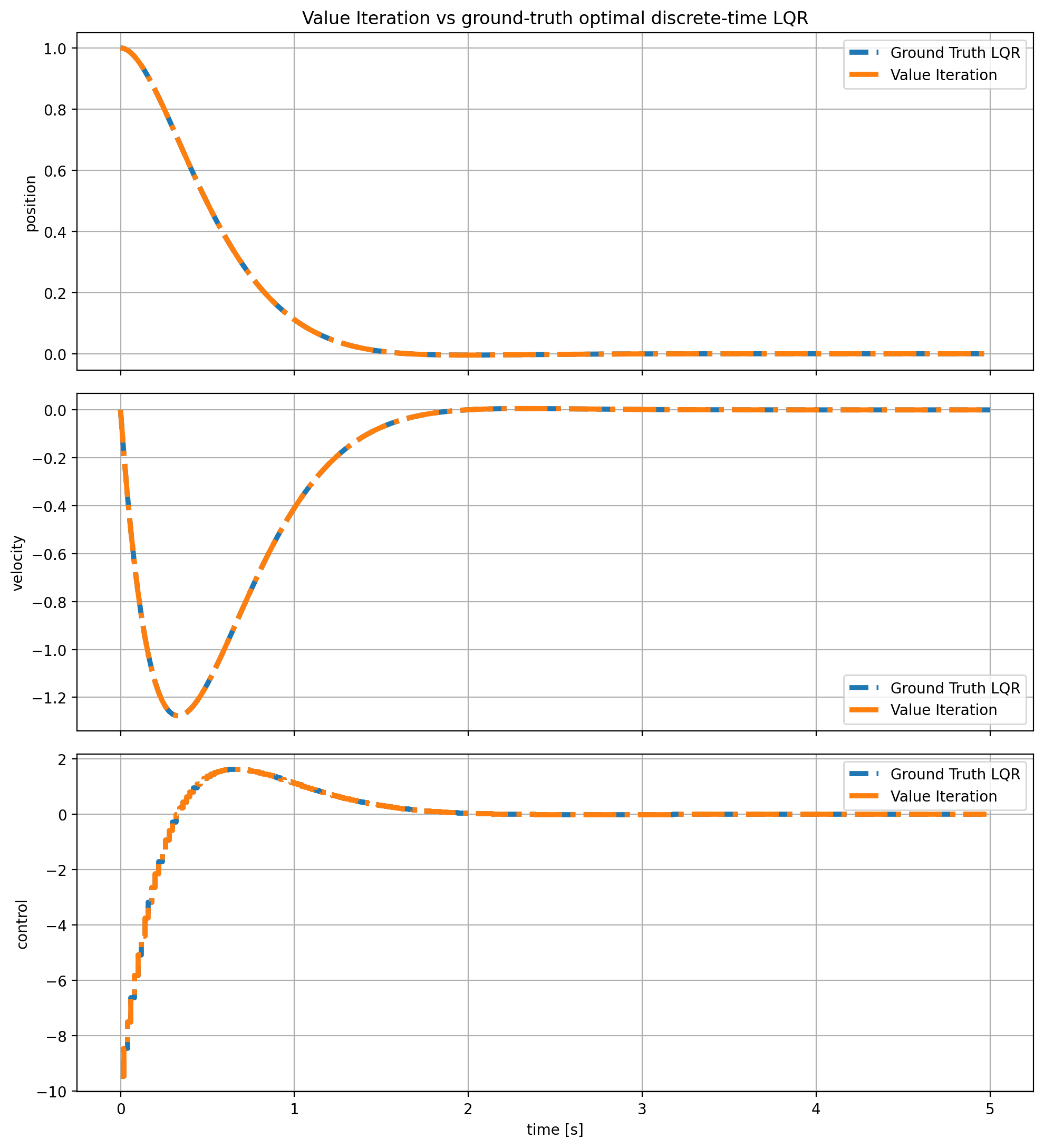
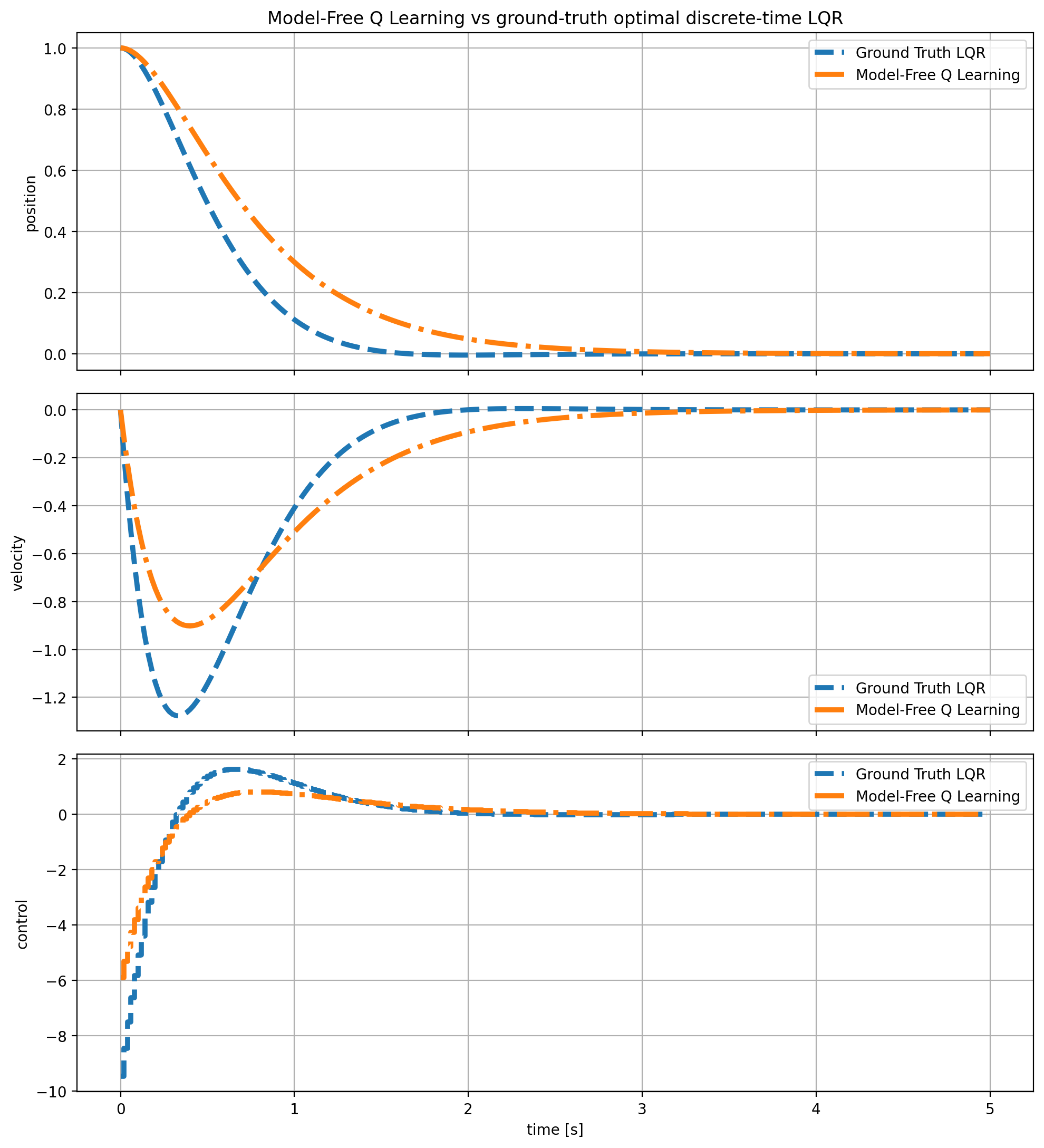
▪ TD3-SAC-Gymnasium
PyTorch implementation of off-policy RL algorithms (TD3 and SAC). Tested in OpenAI Gymnasium.
[Blog Post] [Code]




▪ Trajectory-Tracking-ILC
Use Iterative Learning Control (ILC) for trajectory tracking task with the existence of model mismatch. Model Predictive Control (MPC) is also used for comparison.
[Code] [Report] [Slide]
![]()
publications
A Parametric Thoracic Spine Model Accounting for Geometric Variations by Age, Sex, Stature, and Body Mass Index
Lihan Lian, Michelle Baek, Sunwoo Ma, Monica Jones, Jingwen Hu
SAE International Journal of Transportation Safety (Special Student Issue), 2023
[Paper] [Slide] [Website]
Co-state Neural Network for Real-time Nonlinear Optimal Control with Input Constraints
Lihan Lian, Uduak Inyang-Udoh
American Control Conference (ACC), 2025
[Paper] [arXiv] [Code] [Slide]
Neural Co-state Regulator: A Data-Driven Paradigm for Real-time Optimal Control with Input Constraints
Lihan Lian, Yuxin Tong, Uduak Inyang-Udoh
Conference on Decision and Control (CDC), 2025
[Paper] [arXiv] [Code] [Website]
talks
Talk 1 on Relevant Topic in Your Field Permalink
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Conference Proceeding talk 3 on Relevant Topic in Your Field Permalink
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
teaching
Teaching experience 1 Permalink
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Teaching experience 2 Permalink
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.